스터디 (정리)/BigData
[BigData] Apache Hadoop (HDFS) 정리
LucasRan
2023. 12. 16. 19:36
반응형
1. 정리 목적
- Hadoop에 대한 기본 개념을 살펴본다.
- Hadoop의 기본 구성을 살펴본다.
- Hadoop의 아키텍처를 살펴본다.
- Hadoop을 개인적으로 활용했던 부분을 간단하게 공유한다.
2. Hadoop이란?
- 대용량 데이터를 분산 저장 가능
- 분산 저장된 대용량 데이터를 분석 가능
- 대용량 데이터 처리를 위해 분산 병렬 처리 기술을 사용
※ Hadoop의 MapReduce
Map : 수 많은 분산 컴퓨터에서 일을 효율적으로 나눠서 실행
Reduce : 수 많은 컴퓨터들이 나눠서 만든 결과들을 하나로 모아줌
Hadoop의 MapReduce로 분산 컴퓨터에서 일을 효율적으로 나눠서 실행시키고 그 결과를 하나로 모아주기 쉽게 지원해 준다.
3. Hadoop 구성
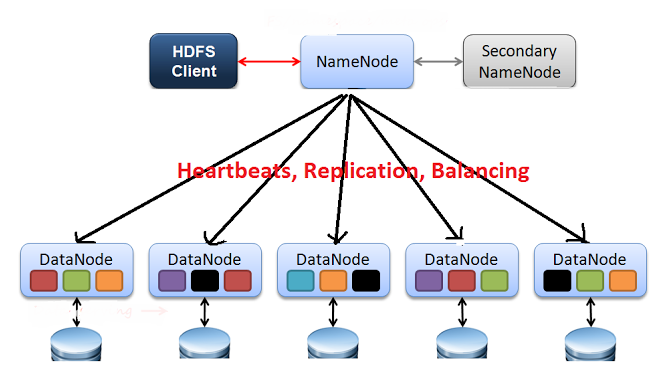
- DataNode : 블록(64MB, 128MB, 256MB 등) 단위로 분할된 대용량 파일들이 DataNode의 디스크에 저장 및 관리
- NameNode : DataNode에 저장된 파일들의 메타 정보를 메모리상에서 로드하여 관리
- Yarn : Hadoop 클러스터 내의 자원을 중앙 관리하면서 작업 요청 시 스케줄링 정책에 따라 자원을 분배해서 실행시키고 모니터링을 함
- ResourceManager : Hadoop 클러스터 내의 자원을 중앙 관리 및 분배 실행, 모니터링
- NodeManager : DataNode마다 실행되면서 Container를 실행, 라이프 사이클 관리
- Container : DataNode의 사용 가능한 리소스(CPU, 메모리, 디스크 등)을 Container 단위로 할당해서 구성
- ApplicationMaster : NodeManager에게 애플리케이션이 실행될 Container를 요청하고 그 위에서 Application을
실행 및 관리 - JournalNode : 3개 이상의 Node로 구성되어 EditsLog를 각 Node에 복제 관리 하며 Active NameNode는 EditsLog에
쓰기만을 수행하고 Standby NameNode는 읽기만을 실행
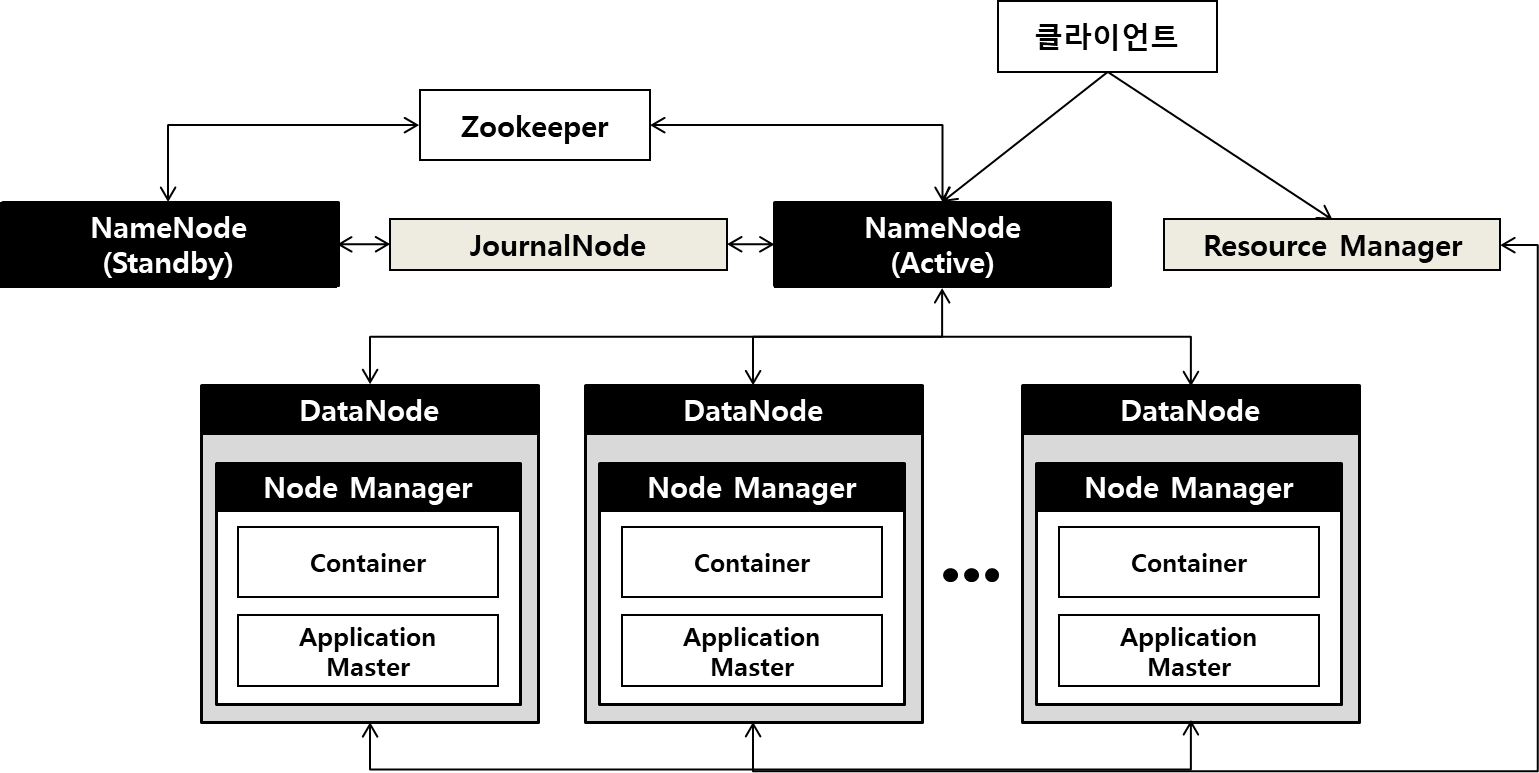
4. Hadoop 아키텍처
- Resource Manager는 Node Manager의 리소스 현황들을 종합적으로 수집하여 작업이 실행되기 위한 최적의 DataNode를 찾아줘서 효율적인 잡 스케줄링이 가능
- NodeManager의 Container, Application Master는 MapReduce job 외에도 다양한 Application을 Hadoop의 DataNode에서 실행 및 관리할 수 있다.
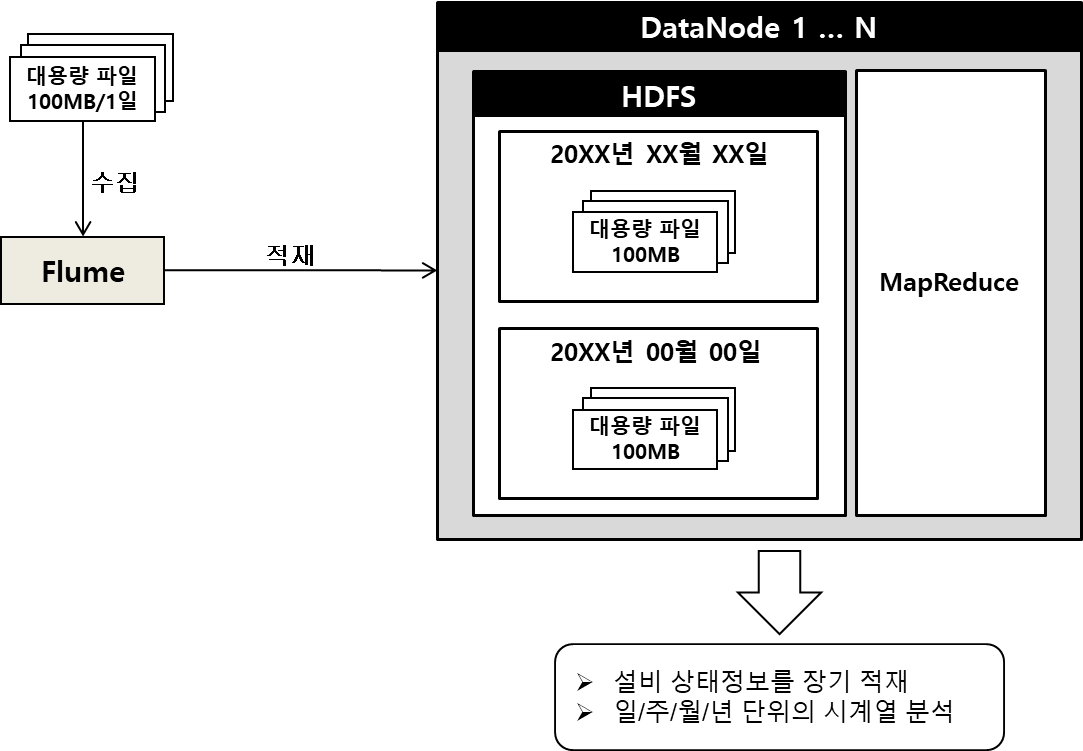
5. Hadoop 활용
- 설비 상태정보를 일/주/월/년 단위로 파티션하여 적재
- 장기간 적재된 상태 정보 데이터들을 다양한 시계열 집계 분석 진행
※ 참조 url :
- https://opentutorials.org/module/2926/17055
하둡(Hadoop) 소개 및 기본 구성요소 설명 - 하둡에 대하여~
하둡이란? 분산 환경에서 빅 데이터를 저장하고 처리할 수 있는 자바 기반의 오픈 소스 프레임 워크. 구성요소 1. 하둡 분산형 파일시스템(Hadoop Distributed FileSystem, HDFS) 하둡 네트워크에 연결된 기
opentutorials.org
- [도서]실무로배우는 빅데이터기술 https://product.kyobobook.co.kr/detail/S000001766428
실무로 배우는 빅데이터 기술 | 김강원 - 교보문고
실무로 배우는 빅데이터 기술 | 전문 개발자가 아니어도 약간의 소프트웨어 지식만으로 빅데이터의 A~Z까지 기술들을 구현하고 경험해 볼 수 있는 파일럿 프로젝트 형식으로 구성했다. 빅데이터
product.kyobobook.co.kr
반응형